Bases de datos no relacionales
Introducción
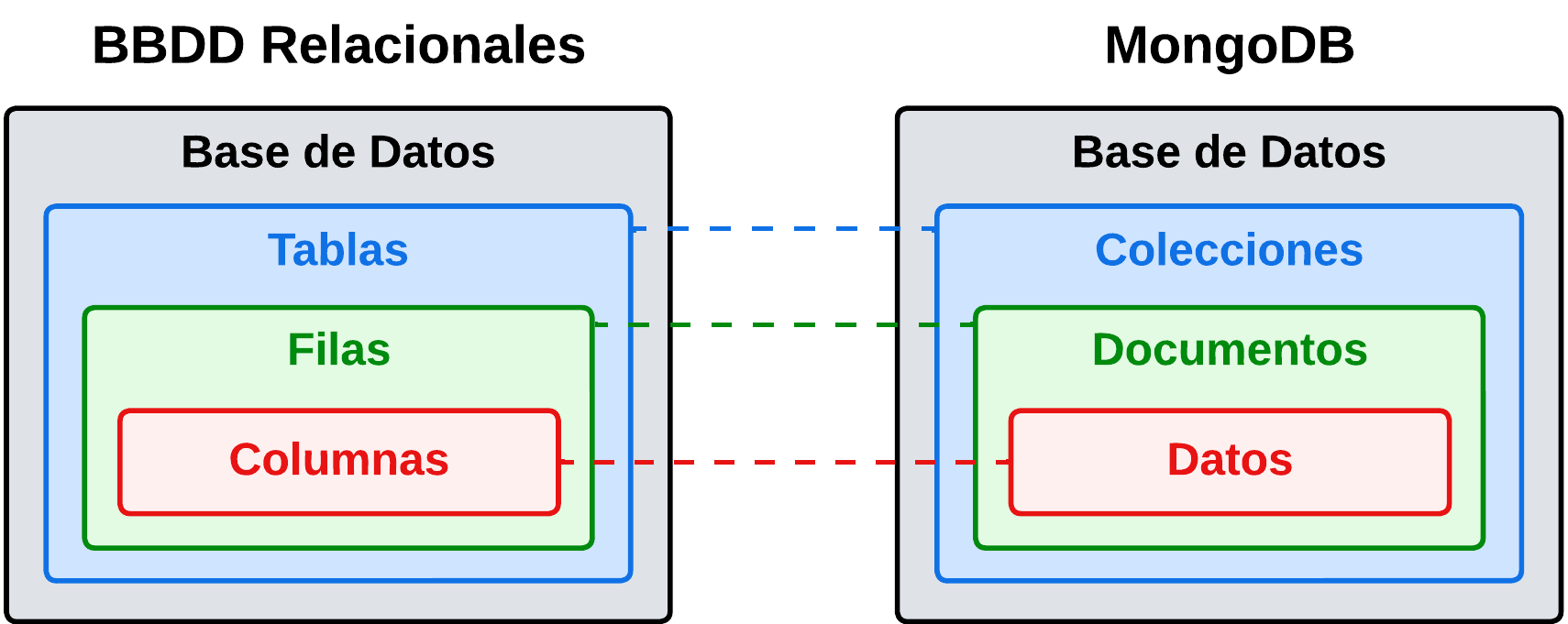
Las bases de datos NoSQL están optimizadas para aplicaciones que requieren grandes volúmenes de datos, baja latencia y modelos de datos flexibles, lo que se logra mediante la flexibilización de algunas de las restricciones de consistencia de datos o por la existencia de un esquema fijo para el modelo de datos.
Este tipo de bases de datos se caracterizan porque no utilizan el esquema relacional, sino que utilizan un modelo de almacenamiento optimizado para el tipo de datos que van a almacenar. En este sentido encontramos datos que se pueden almacenar como pares clave-valor simple, como documentos JSON o como un grafo que consta de aristas y vértices.
Las bases de datos NoSQL se caracterizan por lo siguiente:
Flexibilidad: generalmente ofrecen esquemas flexibles que facilitan un desarrollo iterativo.
Escalabilidad: están diseñadas para escalar usando clústeres distribuidos.
Alto rendimiento: cada tipo de base de datos está optimizada para trabajar con el tipo de datos que posteriormente va a almacenar, lo que asegura que puede disponer de patrones de acceso que permiten un mayor rendimiento.
Altamente funcional: las bases de datos NoSQL proporcionan APIs y tipos de datos altamente funcionales diseñados específicamente para cada uno de los posibles usos.
Motores de búsqueda
Un motor de búsqueda es un componente software que me permite realizar consultas de un modo algo diferente a como se realizan en una base de datos relacional.
En las bases de datos relacionales hay consultas muy complejas y que tienen un alto costo computacional. Además, hay tipos de consultas que no serían efectivas realizarlas en una base de datos relacional, pues podrían requerir de mucha capacidad de la base de datos, restándole capacidad para realizar otras consultas más críticas para el negocio.
Lo que buscamos con los motores de búsqueda es extraer toda la información puramente consultiva y moverla a otro lugar, de forma que podamos realizar consultas mucho más optimizadas.
Esta es la razón por lo que surgieron los motores de búsqueda.
Apache Lucene
Apache Lucene es una librería open source escrita en JAVA.
Implementa un motor de búsqueda de alto rendimiento.
Conceptos clave
A la hora de trabajar con Lucene, el índice es un concepto clave.
Un índice nos permite guardar información estructurada, y dentro de los índices tendremos documentos y metadatos asociados a ellos.
Habilita para realizar búsquedas:
Sobre frases.
Con wildcards.
Sobre metadatos de documentos.
Scored queries.
Funcionamiento
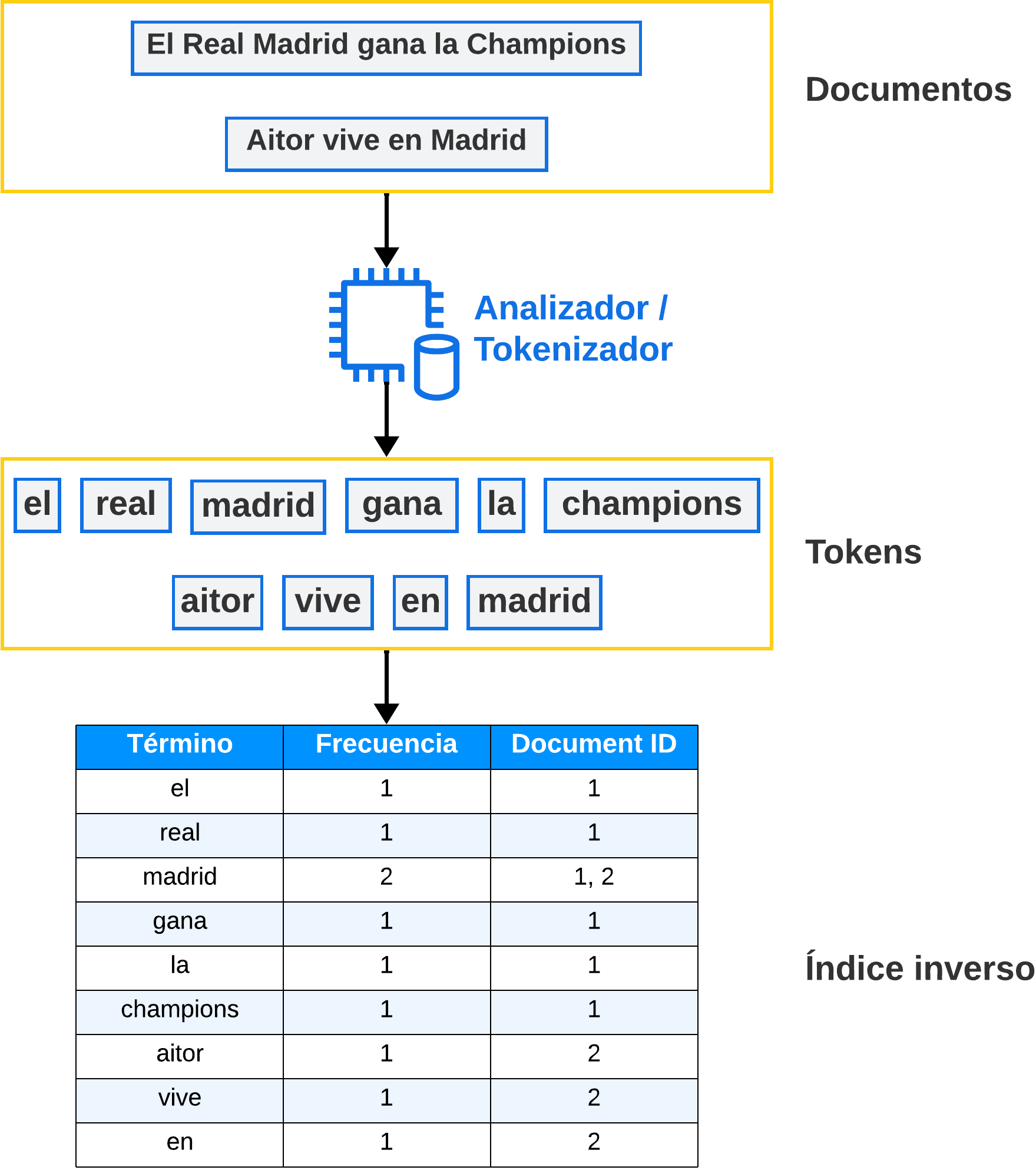
Lucene funciona con índices inversos:
Los documentos pasan por un tokenizador, que trocea los documentos en términos.
Los tokens son insertados en los índices de Lucene.
Cada término se asocia con una referencia al documento en el que aparece.
A la hora de buscar un término, el motor nos traerá los documentos asociados a dicho término.
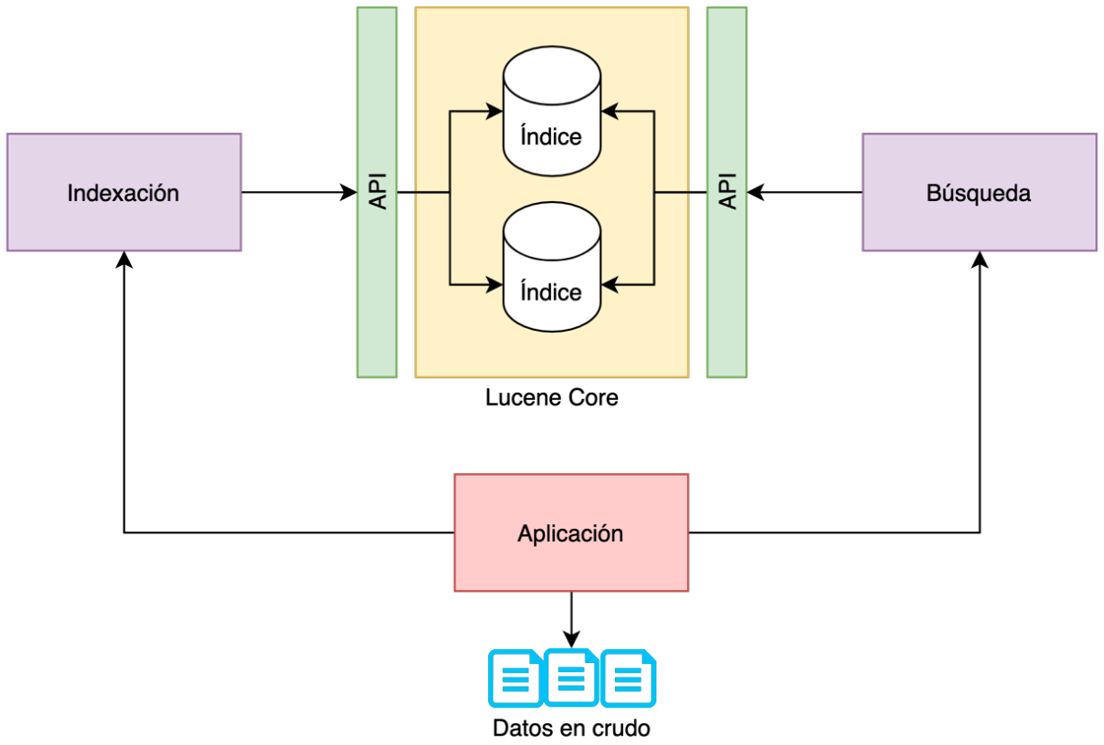
A la hora de trabajar con un motor de búsqueda hay dos fases:
Indexación: a partir de unos datos en crudo, nuestra aplicación deberá indexar esos datos.
Búsqueda: una vez indexados los datos, podremos realizar consultas sobre esos datos.
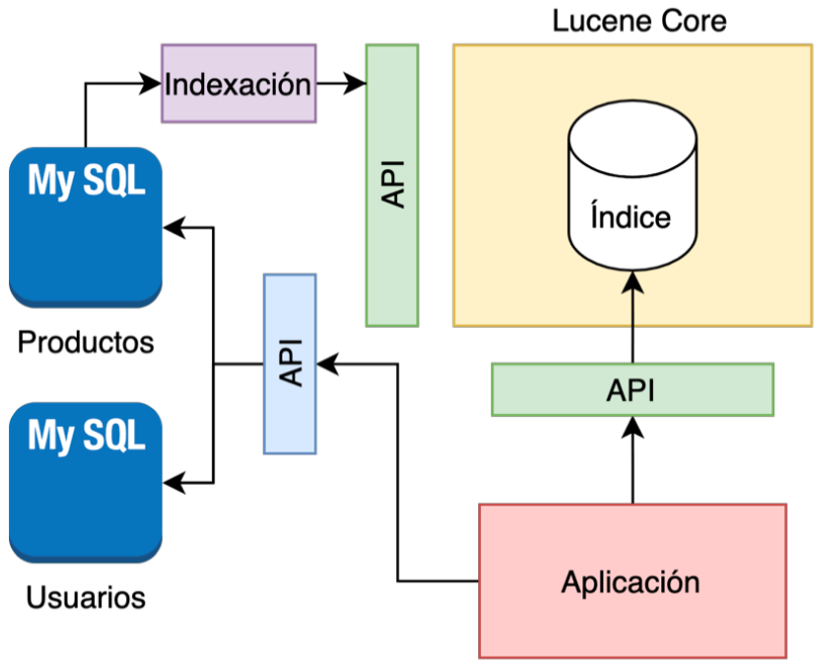
No podemos considerar a Lucene como una base de datos, Lucene es un motor de búsqueda que esta pensado para hacer búsquedas sobre un snapshot de los datos.
Se puede considerar que implementa una base de datos no relacional orientada a documentos, pero no es un soporte válido para un sistema transaccional, no cumple con las propiedades ACID y no tiene garantía de la persistencia.
Debemos mantener nuestros datos en nuestra base de datos relacional y de forma síncrona realizar la indexación de los datos necesarios al motor de búsqueda, de tal forma, que a la hora de realizar consultas, las realizaremos a través del motor de búsqueda y el modelo de negocio lo mantendremos en nuestra bases de datos relacional.
Elasticsearch
Elasticsearch es un motor de búsqueda de datos y analítica desarrollado a partir de Lucene.
Elasticsearch es una plataforma que cubre Lucene y nos ofrece una forma mas cómoda de trabajar con el motor de búsqueda.
Permite gestionar diferentes tipos de datos:
Textuales.
Numéricos.
Geoespaciales.
Estructurados.
No estructurados.
Dado que está desarrollado a partir de Lucene, todas sus características están presentes.
Sin embargo:
Elasticsearch no es una librería, es un producto comercial.
Elasticsearch es un sistema distribuido.
Elasticsearch es un motor de analítica y búsqueda.
Tipos de datos
Textuales
Keyword: Contenido estructurado. Permiten búsquedas exactas. Facilitan agregación y ordenación.
Text: Contenido desestructurado (grandes textos). Tendremos un analizador asociado que por defecto tokenizará cada palabra.
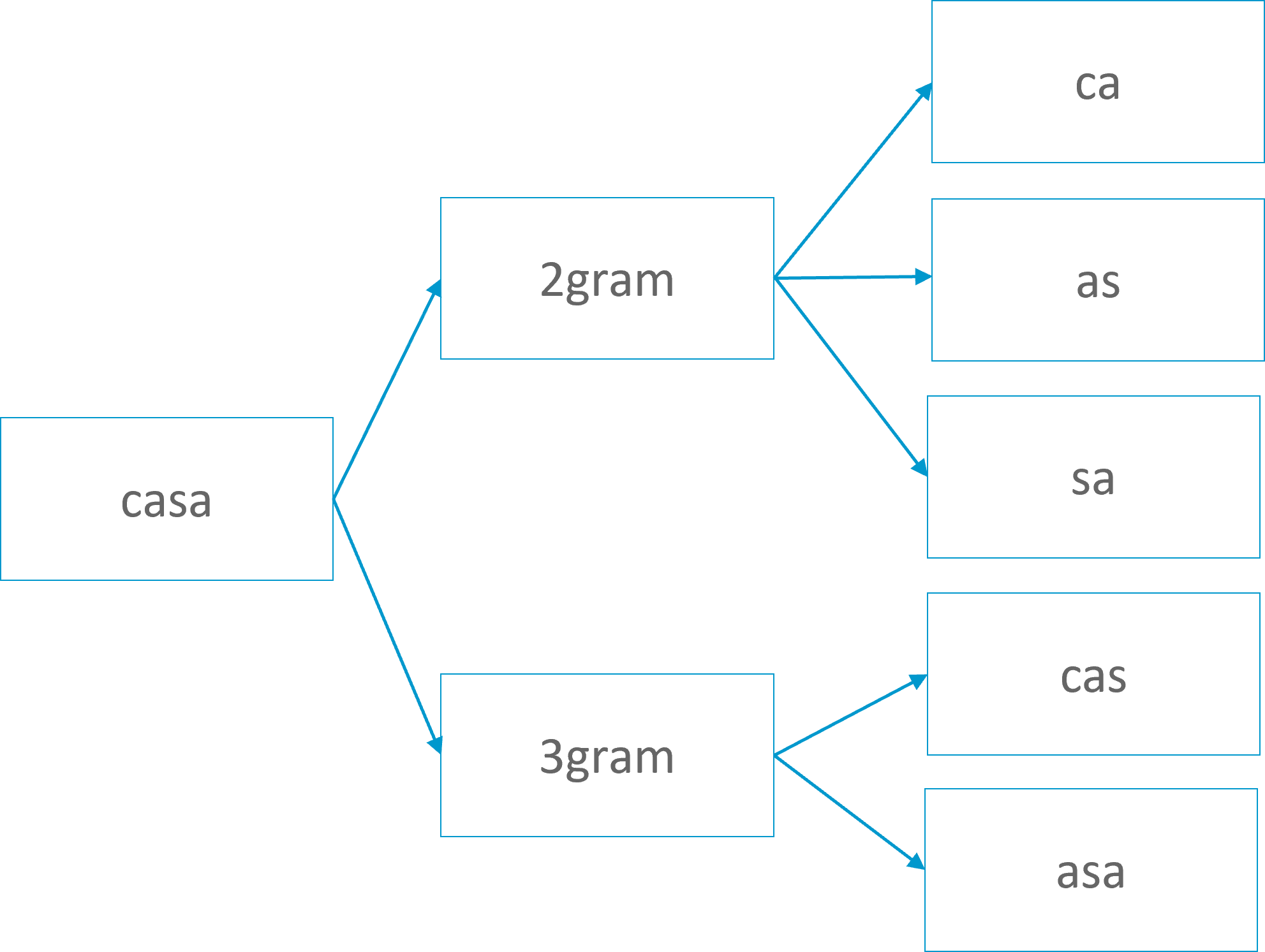
Search as you type: Se usan en correcciones o sugerencias. Para ello divide los tokens en
Objetos
Elasticsearch guarda la información como JSON.
Object: Almacena un JSON que mantendrá su estructura pero que perderá la relación entre subcampos del objeto, en caso de haberlos.
Flattened: Almacena un JSON como una cadena de texto (plano).
Nested: Almacena un JSON igual que Object, pero preservando la relación entre subcampos, habilitando las consultas sobre dichos subcampos.
Otros tipos
Numéricos: Almacenan números. Muy similares a los tipos de datos numéricos de los lenguajes de programación más populares (Long, Intenger, Short, Double, Float…).
Boolean: True o False.
Consultas básicas
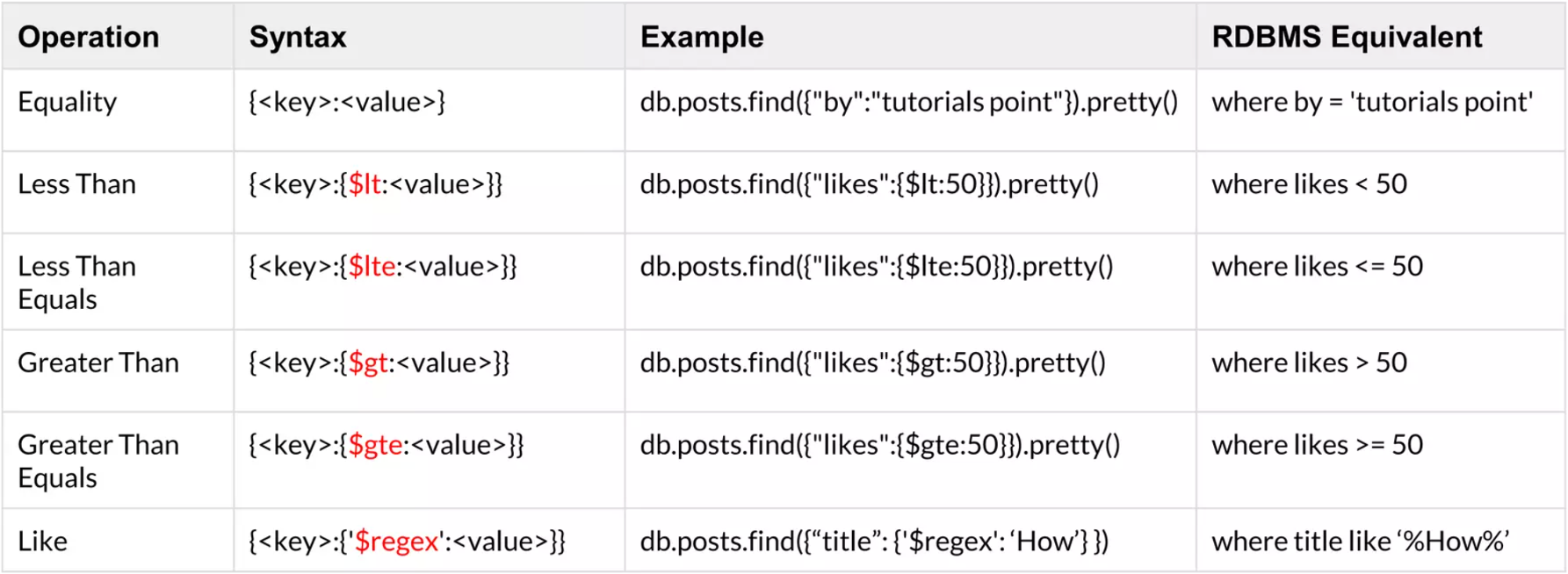
En Elasticsearch las consultas se realizan mediante JSON.
Compuestas (
bool): Las consultas compuestas envuelven otras consultas compuestas u hojas, ya sea para combinar sus resultados y puntuaciones, para cambiar su comportamiento, o para pasar de una consulta a otra Contexto de filtro.Full-Text: Las consultas de texto completo le permiten buscar campos de textos analizados, como el cuerpo de un correo electrónico. La cadena de consulta se procesa con el mismo analizador que se aplicó a durante la indexación.
Term-Level: podemos utilizar consultas de nivel de término para buscar documentos basados en valores precisos en datos estructurados. Algunos ejemplos de datos estructurados son los intervalos de fechas, las direcciones IP, precios o identificadores de productos.
A diferencia de las consultas de texto completo, las consultas de nivel de término no Analice los términos de búsqueda. En su lugar, las consultas de nivel de término coinciden con los términos exactos almacenados en un campo.
Joining: Realizar uniones completas de estilo SQL en un sistema distribuido como Elasticsearch es prohibitivamente caro. En su lugar, Elasticsearch ofrece dos formas de unión que están diseñados para escalar horizontalmente.
nestedqueryLos documentos pueden contener campos de tipo
nested. Estos Los campos se utilizan para indexar matrices de objetos, donde se puede consultar cada objeto (con la consulta) como un documento independiente.nestedhas_childyhas_parentPuede existir una relación de
joinentre documentos dentro de un único índice. La consulta devuelve el elemento primario documentos cuyos documentos secundarios coincidan con la consulta especificada, mientras que la consulta devuelve documentos secundarios cuyo documento primario coincida con el consulta especificada.has_childhas_parent
Filtros: A continuación se muestra un ejemplo de cláusulas de consulta que se utilizan en el contexto de consulta y filtro en la API. Esta consulta coincidirá con los documentos en los que se cumplan todas las siguientes características.
xxxxxxxxxx151GET /_search2{3"query": {4"bool": {5"must": [6{ "match": { "title": "Search" }},7{ "match": { "content": "Elasticsearch" }}8],9"filter": [10{ "term": { "status": "published" }},11{ "range": { "publish_date": { "gte": "2015-01-01" }}}12]13}14}15}Se cumplen las siguientes condiciones:
El campo
titlecontiene la palabra"search".El campo
contentcontiene la palabra"elasticsearch".El campo
statuscontiene la palabra exacta"published".El campo
publish_datecontiene una fecha a partir del 1 de enero de 2015.
Bases de datos orientadas a documentos
El concepto central de una base de datos orientada a documentos es el documento.
Cada implementación de base de datos encapsulan y codifican los datos siguiendo algún formato estándar (JSON, BSON, XML, YAML...)
Al igual que en los sistemas de bases de datos relacionales los documentos actúan como registros (o filas), sin embargo, la flexibilidad hace que dos registros no sean iguales.
Ejemplo:
Empleado 1:
xxxxxxxxxx51{2empleadoId: "CG1"3nombre: "Carlos García"4salario: 450005}Empleado 2:
xxxxxxxxxx91{2empleadoId: "MG1"3nombre: "María González"4salario: 500005Proyectos: [6"gestión-riesgos",7"detección-fraude"8]9}
El primer documento solo tiene información básica de un empleado, en cambio el segundo documento tiene más información, añadiendo así más datos sobre el empleado.
Este tipo de base de datos es adecuado para la gestión de catálogos, perfiles de usuario, o sistemas de gestión de contenido donde cada documento es único y evoluciona con el tiempo.
MongoDB
MongoDB es una base de datos escalable y distribuida open source, que está diseñada para ser extremadamente rápida.
Es posible acceder a sus datos con SDKs para varios lenguajes de programación pero su lenguaje característico es MQL (MongoDB Query Language).
Su utiliza principalmente cuando se desea almacenar mucha información y que sea consumida de forma rápida, sin necesidad de transaccionalidad estricta y de integridad referencial (Aplicaciones Web, SaaS, Gaming…).
Elementos esenciales
Colecciones
La colección es la agrupación principal de información en MongoDB y pueden crearse con anterioridad o la primera vez que son referenciadas (on-the-fly). Pensemos en ellas como las “tablas” que teníamos en bases de datos relacionales.
No hay schemas predefinidos, puesto que se almacenan documentos (JSON - BSON) que pueden variar.
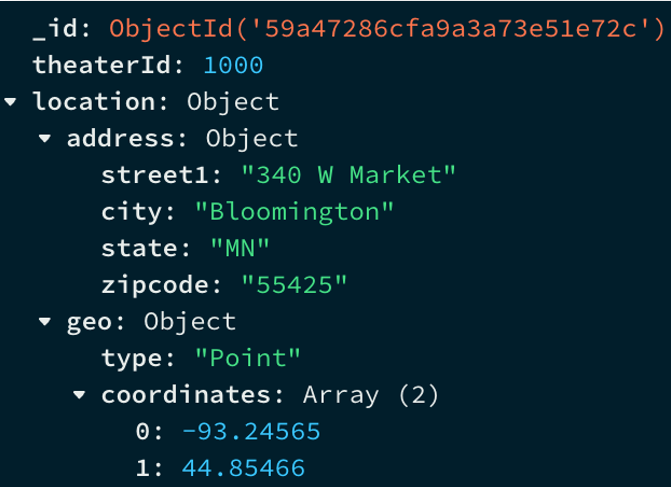
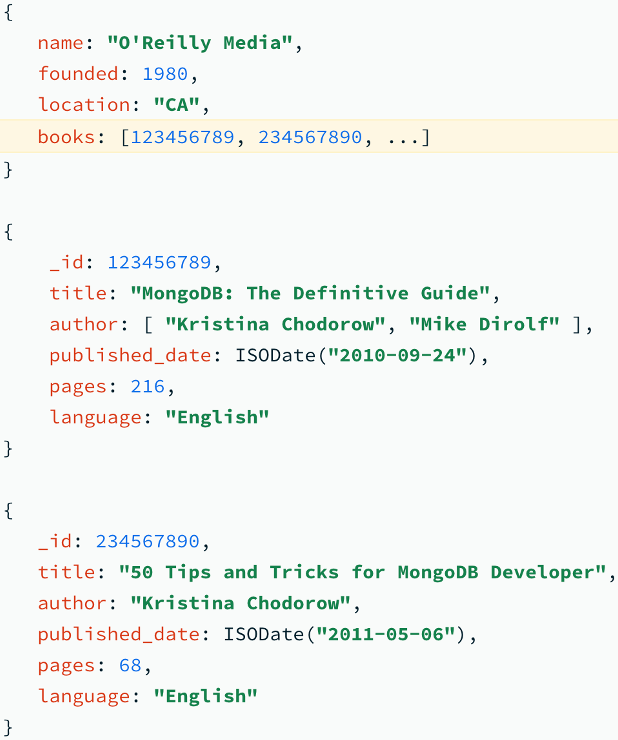
Documentos
Son los elementos que se almacenan dentro de las colecciones y son indexables por una o varias claves.
Todos los documentos tienen un atributo _id que se asemeja a la PK de una tabla relacional.
En MongoDB solo se soportan dos tipos de relaciones:
Embedded (Embebidos): Un documento dentro de otro.
References (Referenciados): A través de referencias. ¡OJO!, no hay integridad referencial.
Se almacenan en BSON (Binary JSON).
Índices
Se pueden crear para cualquier campo de un documento.
Hay que tener en cuenta que los índices aplican las mismas consideraciones que los índices de las bases de datos relacionales, como el espacio.
Los documentos son indexables por una o varias claves.
Consultas
JOINS
Se puede usar referencias para referenciar documentos relacionados. No hay integridad referencial auténtica.
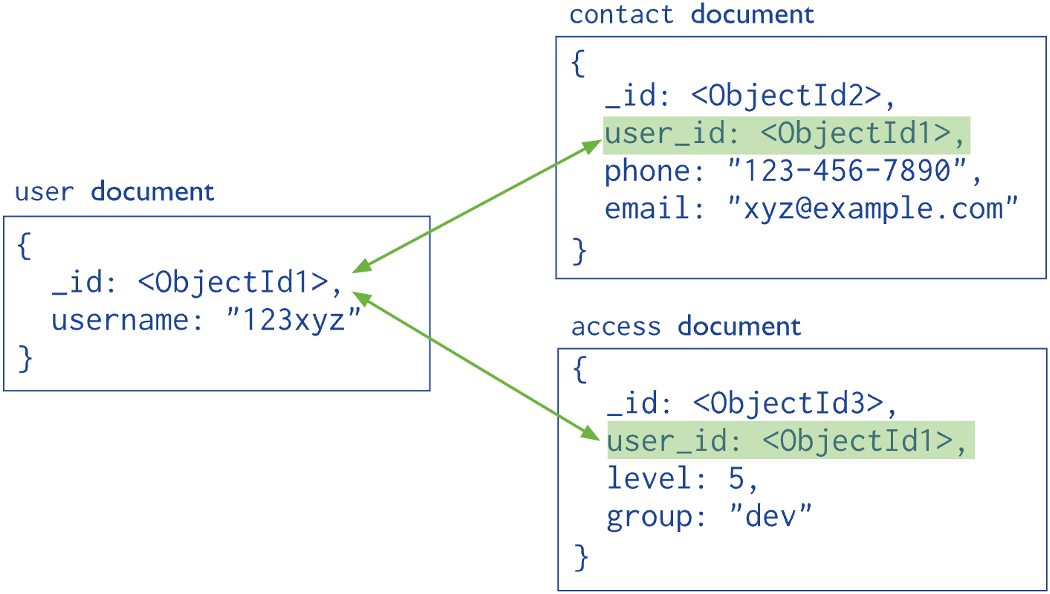
Una eliminación de un user no implicaría una eliminación de contact.
Si no se gestiona correctamente se pueden dar situaciones de orfandad.
Hay varios tipos de referenciación y dependen del caso de uso.
 |
 |
 |
|---|
Bases de datos clave-valor
Una base de datos clave-valor se asemeja a una tabla hash grande. Cada valor de datos está asociado con una clave única y se usará esta clave para almacenar los datos mediante el uso de una función hash apropiada.
Al igual que las bases de datos orientadas a documentos, las bases de datos clave-valor no necesitan que el esquema esté definido previamente.
Los sistemas de bases de datos clave-valor están muy optimizados para aplicaciones que realizan búsquedas simples mediante el valor de la clave, sin embargo, son menos adecuados para aquellas aplicaciones que necesitan consultar datos en diferentes tablas de claves-valores. Este tipo de base de datos es adecuada para mantener la sesión en las aplicaciones web o para almacenar el carro de la compra de un e-commerce.
Redis
Redis (Remote Dictionary Server) es una base de datos en memoria open source, que nos ofrece una base de datos que puede ser distribuida mediante el almacenamiento clave-valor con durabilidad configurable (TTL, Time To Live).
Su uso principal es como caché de peticiones HTTP, sesiones HTTP, cookies...
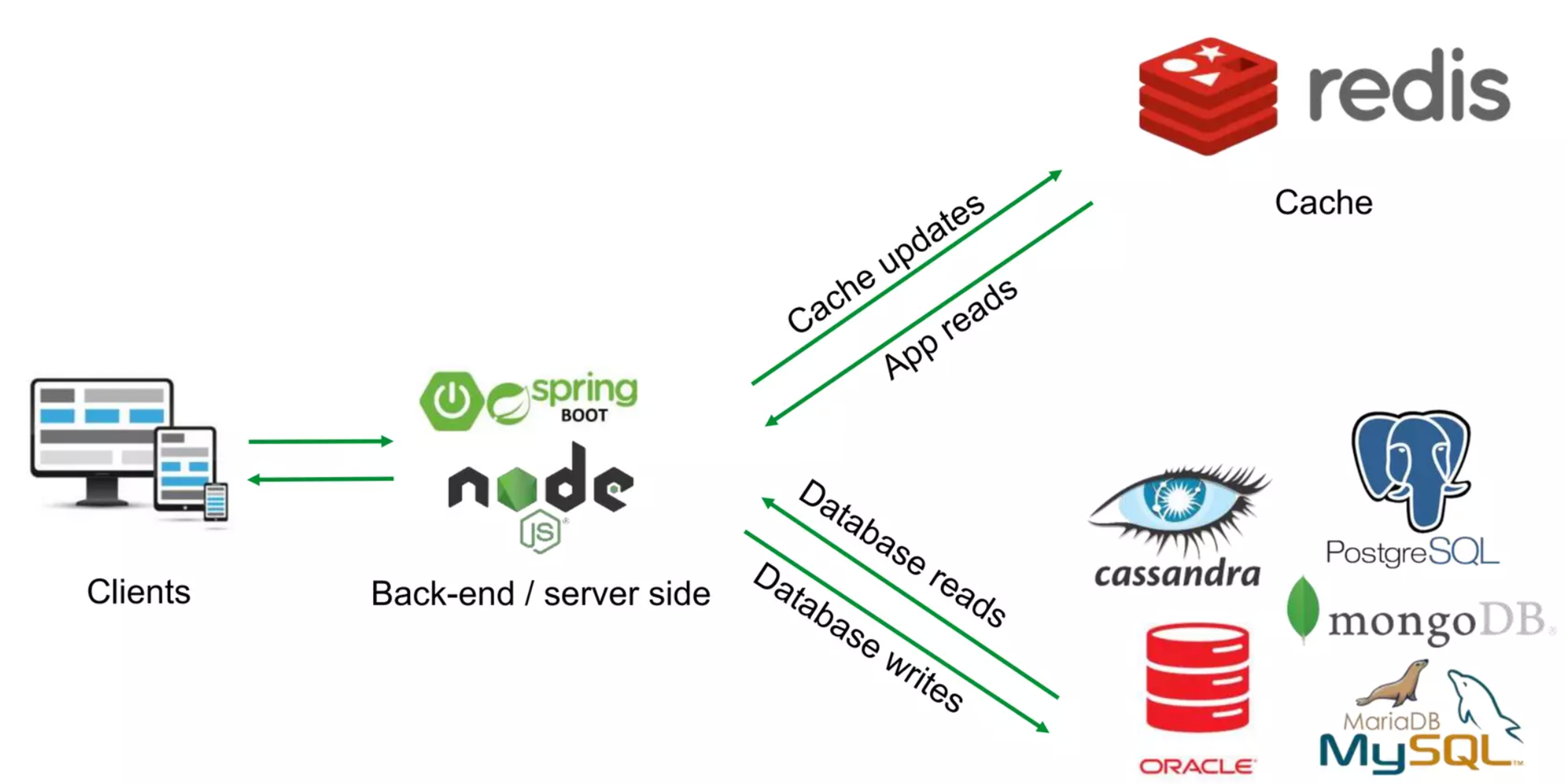
Las lecturas irán contra la caché Redis y las escrituras contra la base de datos principal. Esto se suele hacer para no saturar la base de datos con las lecturas.
Tipos de datos más utilizados
Strings
Redis almacena todo como Strings (Strings, Bytes, Integer, Floats, Booleans) y su tamaño máximo son 512MB.
xxxxxxxxxx161127.0.0.1:6379> SET greeting 'Hello' //Guarada un registro2OK //Respuesta3
4/********************************************************/ 5 6127.0.0.1:6379> GET greeting //Recupera un registro7'Hello' //Devuelve el registro8
9/********************************************************/ 10 11127.0.0.1:6379> DEL greeting 'Hello' //Elimina el registro12(integer) 1 //La cantidad de registros afectados13 14/********************************************************/ 15127.0.0.1:6379> EXISTS greeting //Comprueba si algo existe16(integer) 0 //La cantidad de registros encontrados
xxxxxxxxxx221127.0.0.1:6379> SET greeting 'Hello' //Guarada un registro2OK //Respuesta3
4/********************************************************/ 5 6127.0.0.1:6379> EXPIRE greeting 10 //Asigna el TTL a un registro 7(integer) 1 //La cantidad de registros afectados8
9/********************************************************/ 10 11127.0.0.1:6379> TTL greeting //TTL restante de un registro12(integer) 8 //TTL restante del registro13 14/********************************************************/ 15
16127.0.0.1:6379> GET greeting //Recupera un registro17'Hello' //Devuelve el registro18
19/********************************************************/ 20 21127.0.0.1:6379> GET greeting //Recupera un registro22(nil) //El registro ha expirado List (Listas con repeticiones)
xxxxxxxxxx281127.0.0.1:6379> LPUSH people 'Maarten' //Añadir un elemento a una lista por la izquierda2(integer) 1 //La cantidad de elementos de la lista3 4/********************************************************/5 6127.0.0.1:6379> RPUSH people 'John' //Añadir un elemento a una lista por la derecha7(integer) 2 //La cantidad de elementos de la lista8 9/********************************************************/10 11127.0.0.1:6379> LRANGE people 0-1 //Consultar un rango concreto de registros de una lista12'Maarten'13'Jhon' 14 15/********************************************************/16 17127.0.0.1:6379> LLEN people //Consultar la longitud de una lista18(integer) 2 // Longitud de la lista19 20/********************************************************/21 22127.0.0.1:6379> LPOP people //Sacar elemento por la izquierda23'Maarten' 24 25/********************************************************/26 27127.0.0.1:6379> RPOP people //Sacar elemento por la derecha28'Jhon'Set (Listas sin repeticiones)
xxxxxxxxxx381127.0.0.1:6379> SADD cars 'Honda' //Añadir un elemento a un Set 2(integer) 1 //La cantidad de elementos añadidos3 4/********************************************************/5 6127.0.0.1:6379> SADD cars 'Ford' //Añadir un elemento a un Set 7(integer) 1 //La cantidad de elementos añadidos8 9/********************************************************/10 11127.0.0.1:6379> SADD cars 'Honda' //Añadir un elemento a un Set 12(integer) 0 //La cantidad de elementos añadidos "No Duplicados"13 14/********************************************************/15 16127.0.0.1:6379> SISMEMBER cars 'Honda' //Si un elemento forma parte de un Set 17(integer) 1 //La cantidad de elementos encontrados18 19/********************************************************/20 21127.0.0.1:6379> SISMEMBER cars 'BMW' //Si un elemento forma parte de un Set 22(integer) 0 //La cantidad de elementos encontrados23 24/********************************************************/25 26127.0.0.1:6379> SMEMBER cars //Elementos de un Set27'Ford'28'Honda'29 30/********************************************************/31 32127.0.0.1:6379> SMOVE cars mycars 'Honda' //Mover elemento de un Set a otro 33(integer) 1 //La cantidad de elementos afectados34 35/********************************************************/36 37127.0.0.1:6379> SDIFF cars mycars //Diferencia entre Sets 38'Ford' //Elemento diferente encontrado Hashes
Ideal para almacenar objetos.
xxxxxxxxxx291127.0.0.1:6379> HMSET user:1000 username antirez password P1pp0 age 34 //insertar un HasH 2OK //Respuesta3 4/********************************************************/5 6127.0.0.1:6379> HGETALL user:1000 //Obtener todos los elementos de un HasH 7'username'8'antirez'9'password'10'P1pp0'11'age'12'34'13 14/********************************************************/15 16127.0.0.1:6379> HSET user:1000 password 12345 //Setear un HasH 17(integer) 0 //Respuesta18 19/********************************************************/20 21127.0.0.1:6379> HGET user:1000 password //Setear un HasH 2212345 //Respuesta23 24/********************************************************/25 26127.0.0.1:6379> HKEYS user:1000 //Obtener las claves de un HasH 27'username'28'password'29'age'
Amazon DynamoDB
DynamoDB es una base de datos clave-valor vitaminada, ya que tiene bastante más funcionalidades que otras bases de datos de este tipo.
Ofrece un servicio de base de datos no relacional totalmente gestionado (PaaS).
Estructura básica de una tabla
Nunca debió llamarse tabla. NO es una tabla de una base de datos relacional.
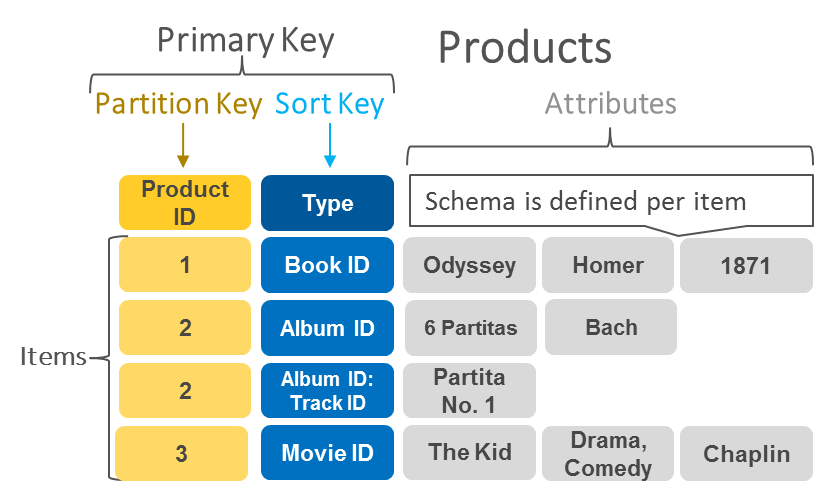
En la tabla tenemos:
Primary Key (PK): la clave de cada uno de los registros que se almacenen en la tabla.
Las PK pueden estar formadas por uno o dos campos, no existen claves compuestas de más de dos campos.
Si solo hay un atributo como PK, ese atributo será la PK y a su vez la Partition Key (clave de partición).
En el caso de haber dos atributos como PK, este segundo atributo será la Sort Key (clave de ordenación).
DynamoDB tiene los datos distribuidos en particiones, así que utiliza la Partition Key para particional la totalidad de nuestros datos y los mantiene ordenados a partir de la Sort Key.
Atributos: para cada una de las PK tendremos una serie de atributos, que al ser una base de datos clave-valor pueden ser variables, pues no tienen un esquema fijo.
En DynamoDB solo tenemos dos operaciones de consulta:
Scan(Examen): devuelve todos los elementos de una tabla.GetItem(Consulta): devuelve los atributos de un elemento que coincidan con la Primary Key o con la Partition Key, pero nunca se pueden realizar las consultas de este tipo sobre la Sort Key.
Índices en DynamoDB
LSI (Local Secondary Index): Son índices donde la clave de partición se mantiene y se permite cambiar la clave de ordenación. Comparten RCU y WCU con la tabla de la cuál nacen. Solo se pueden crear cuando la tabla se crea.
GSI (Global Secondary Index): Son índices donde se permite definir una nueva clave de partición y, opcionalmente, de ordenación para una tabla. No comparten RCU y WCU con la tabla de la cuál nacen. Se pueden crear tras la creación de la tabla.
Bases de datos orientadas a grafos
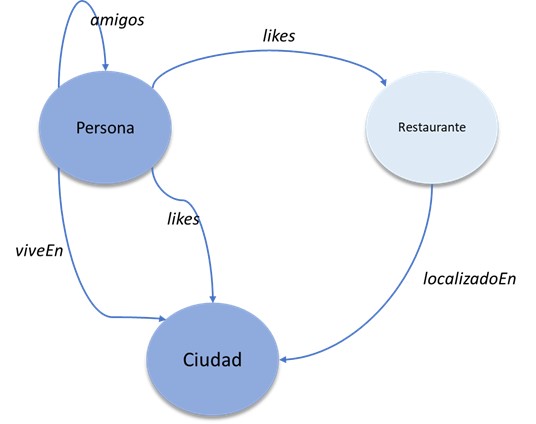
En las bases de datos orientadas a grafos se administran dos tipos de información: el nodo y la arista. Los nodos representan las entidades y las aristas representan las relaciones que las unen. Las aristas pueden tener dirección que indicará la naturaleza de la relación. Las aristas siempre deben tener un nodo de inicio, uno de final, un tipo y una dirección. No existe un límite para la cantidad ni el tipo de relaciones que un nodo puede tener.
Las bases de datos orientadas a grafos tienen una fuerte orientación semántica. Los diferentes nodos se interconectan mediante relaciones y a esa conjunción se le denomina tripleta. «sujeto» «verbo» «objeto».
Este tipo de bases de datos son muy utilizadas en redes sociales, en los sistemas de recomendación y en la detección de fraude, donde se necesita crear relaciones entre los datos y consultarlas rápidamente.
Actualmente existen diversas bases de datos orientadas a grafo, siendo Neo4j la más utilizada. También encontramos OrientDB, Infinite Graph o AllegroGraph.
Neo4J
Neo4J es una base de datos open source, que ofrece una base de datos que puede ser distribuida y que almacena información mediante la estructura de datos grafo.
Es posible acceder a sus datos con SDKs para varios lenguajes de programación, pero su lenguaje característico es Cypher.
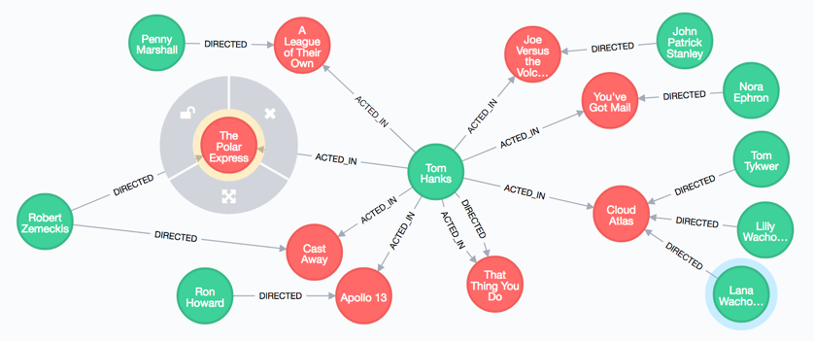
Caso de uso
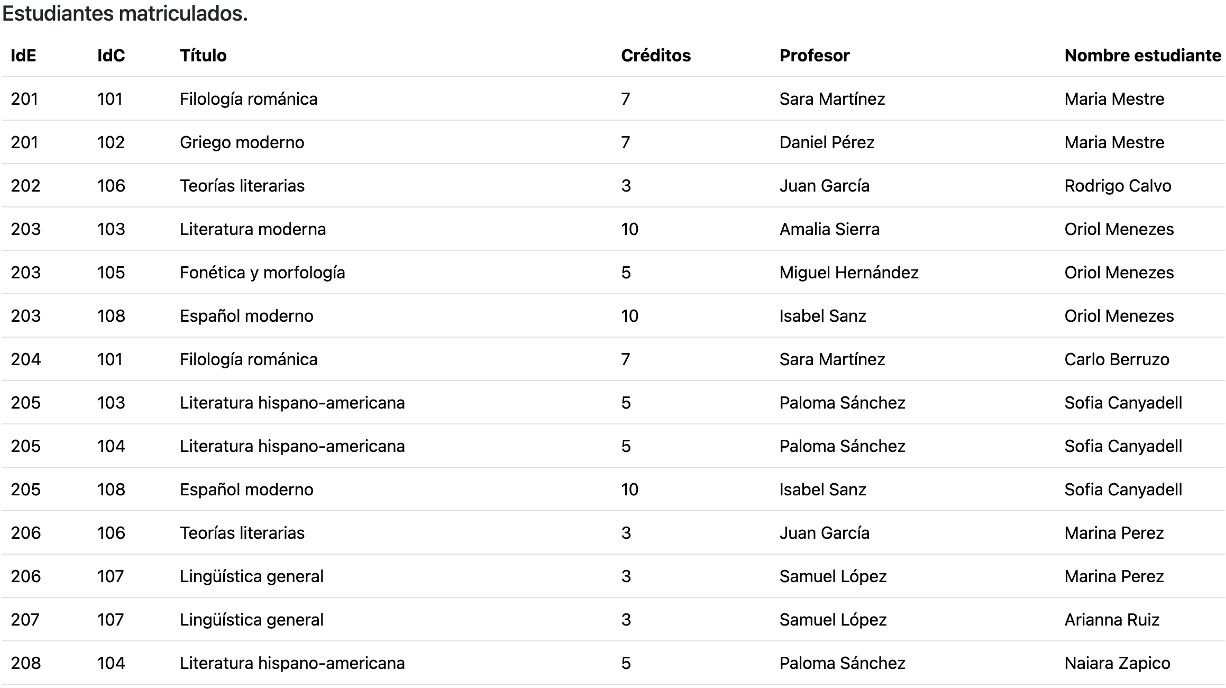
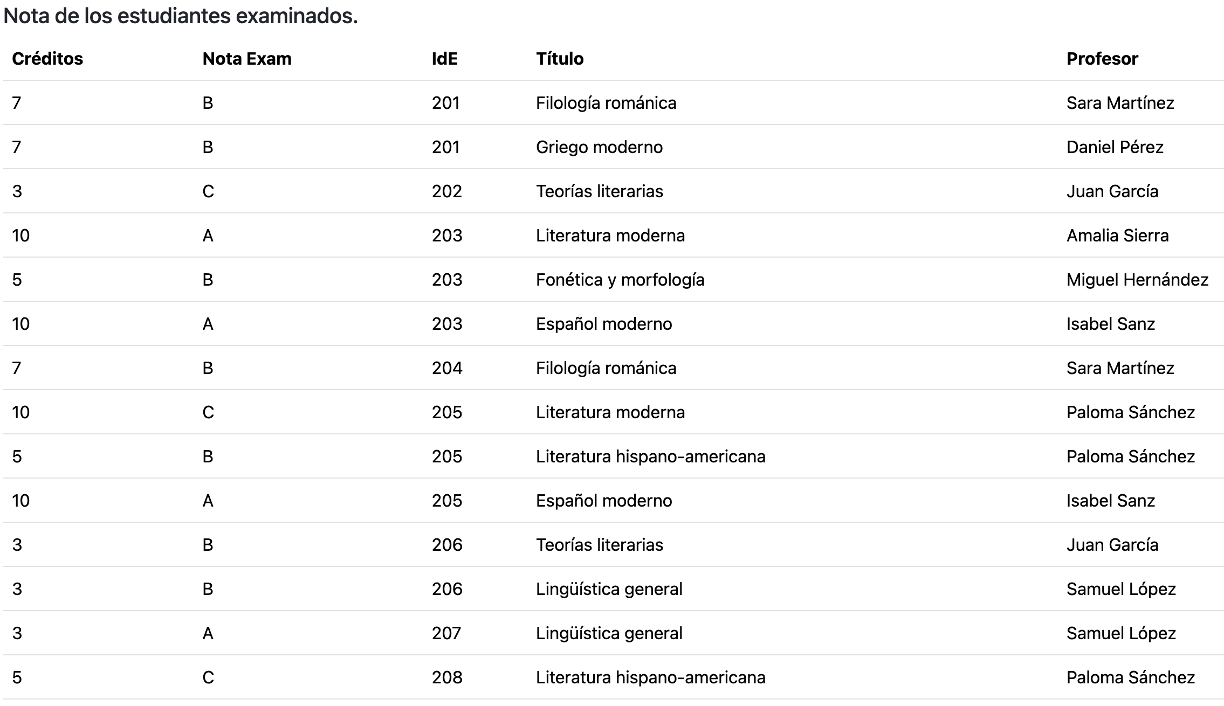
Se desea diseñar una base de datos usando Neo4J para almacenar información de alumnos y exámenes.
 |
 |
|---|
Parte I: Identificar Modelo de Grafo
Lo primero que debemos hacer es establecer el modelo de grafo en base a los datos que queremos almacenar y la forma por la que los vamos a consultar.
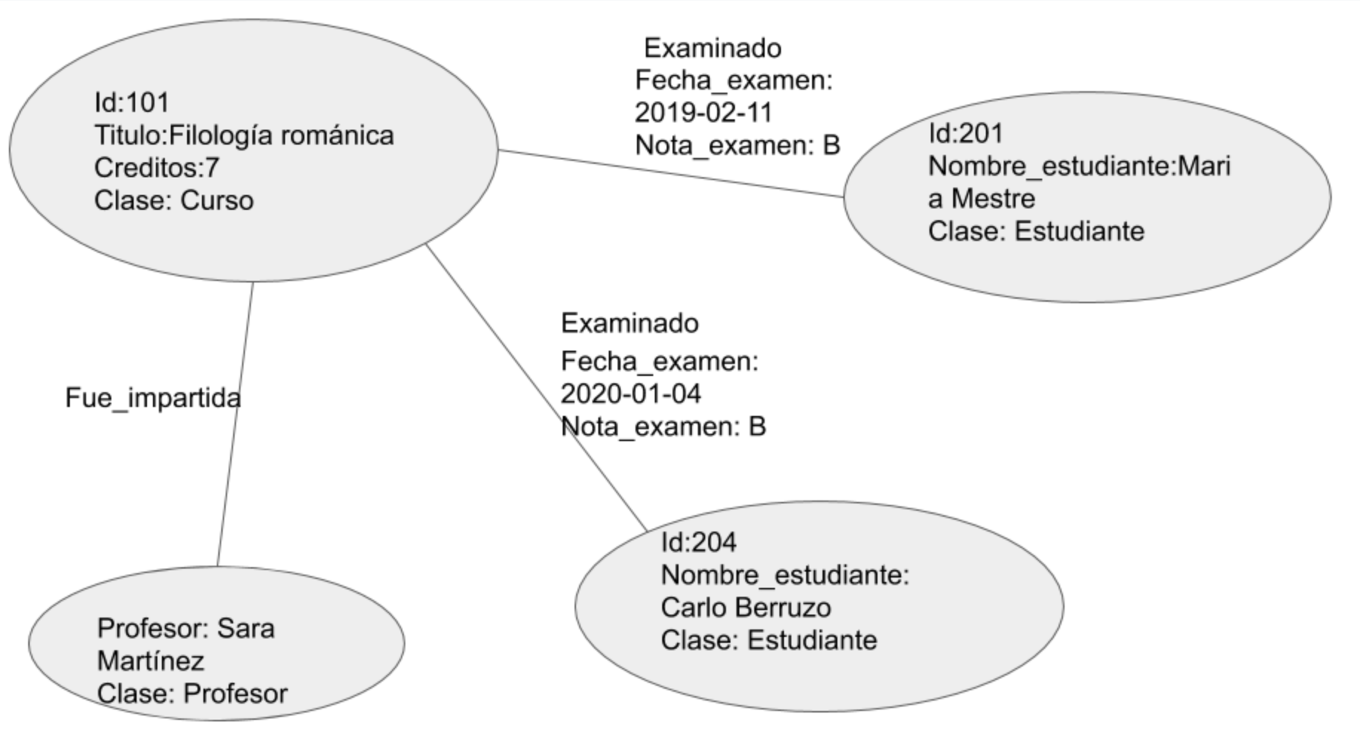
Parte II: Insertar datos
Con Cypher no existe el concepto de DDL. Simplemente insertamos datos y los relacionamos como queramos.
xxxxxxxxxx91CREATE2(p1:Profesor{ profesor:'Sara Martínez'}),3(p2:Profesor{ profesor:'Daniel Pérez'}),4(p3:Profesor{ profesor:'Amalia Sierra'}),5(p4:Profesor{ profesor:'Paloma Sánchez'}),6(p5:Profesor{ profesor:'Miguel Hernández'}),7(p6:Profesor{ profesor:'Juan García'}),8(p7:Profesor{ profesor:'Samuel López'}),9(p8:Profesor{ profesor:'Isabel Sanz'});
xxxxxxxxxx91CREATE 2(e1:Estudiante{ ide: 201 ,estudiante:'Maria Mestre'}),3(e2:Estudiante{ide: 202 , estudiante:'Rodrigo Calvo'}),4(e3:Estudiante{ ide: 203 ,estudiante:'Oriol Menezes'}),5(e4:Estudiante{ ide: 204 ,estudiante:'Carlo Berruzo'}),6(e5:Estudiante{ide: 205, estudiante:'Sofia Canyadell'}),7(e6:Estudiante{ide: 206 , estudiante:'Marina Perez'}),8(e7:Estudiante{ ide: 207 ,estudiante:'Arianna Ruiz'}),9(e8:Estudiante{ ide: 208 ,estudiante:'Naiara Zapico'});
xxxxxxxxxx91CREATE2(c1: Curso { idc: 101 , titulo:'Filología románica', creditos: 7}),3(c2: Curso { idc: 102 , titulo:'Griego moderno', creditos: 7}),4(c3: Curso { idc: 103 , titulo:'Literatura moderna', creditos: 10}),5(c4: Curso { idc: 104 , titulo:'Literatura hispano-americana', creditos: 5}),6(c5: Curso { idc: 105 , titulo:'Fonética y morfología', creditos: 5}),7(c6: Curso { idc: 106 , titulo:'Teorías literarias', creditos: 3}),8(c7: Curso { idc: 107 , titulo:'Lingüística general', creditos: 3}),9(c8: Curso { idc: 108 , titulo:'Español moderno', creditos: 10});
Parte III: Insertar relaciones
xxxxxxxxxx91CREATE2(c1)-[imp1:FUE_IMPARTIDA]->(p1),3(c2)-[imp2:FUE_IMPARTIDA]->(p2),4(c3)-[imp3:FUE_IMPARTIDA]->(p3),5(c4)-[imp4:FUE_IMPARTIDA]->(p4),6(c5)-[imp5:FUE_IMPARTIDA]->(p5),7(c6)-[imp6:FUE_IMPARTIDA]->(p6),8(c7)-[imp7:FUE_IMPARTIDA]->(p7),9(c8)-[imp8:FUE_IMPARTIDA]->(p8);
xxxxxxxxxx151CREATE2(e1)-[exam1:EXAMINADO{ nota:'B' , fecha:date("2019-02-11")}]->(c1),3(e1)-[exam2:EXAMINADO{nota:'B',fecha:date("2018-06-30") }]->(c2),4(e2 )-[exam3:EXAMINADO{nota:'C',fecha:date("2018-06-30")}]->(c6),5(e3 )-[exam4:EXAMINADO{nota:'A',fecha:date("2019-02-11")}]->(c3),6(e3 )-[exam5:EXAMINADO{nota:'A',fecha:date("2018-06-30")}]->(c8),7(e3 )-[exam6:EXAMINADO{nota:'B',fecha:date("2020-01-04")}]->(c5),8(e4 )-[exam7:EXAMINADO{nota:'B',fecha:date("2020-01-04")}]->(c1),9(e5 )-[exam8:EXAMINADO{nota:'C',fecha:date("2020-01-04")}]->(c3),10(e5 )-[exam9:EXAMINADO{nota:'B',fecha:date("2018-06-30")}]->(c4),11(e5 )-[exam10:EXAMINADO{nota:'A',fecha:date("2019-02-11")}]->(c8),12(e6 )-[exam11:EXAMINADO{nota:'B',fecha:date("2018-06-30")}]->(c7),13(e6 )-[exam12:EXAMINADO{nota:'B',fecha:date("2020-01-04")}]->(c6),14(e7 )-[exam13:EXAMINADO{nota:'A',fecha:date("2019-02-11")}]->(c7),15(e8 )-[exam14:EXAMINADO{nota:'C',fecha:date("2019-02-11")}]->(c4);
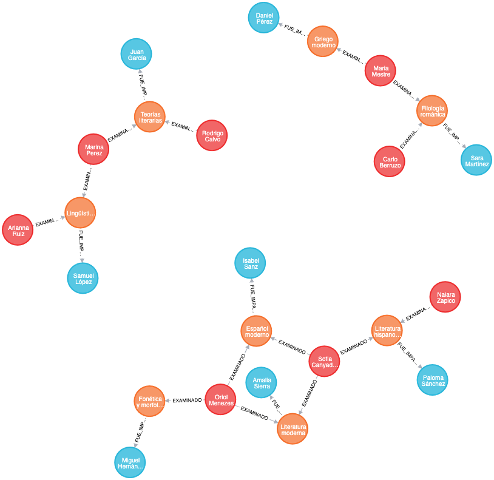
Parte IV: Consultas
Tenemos que especificar mediante tripletas qué información tenemos (los filtros que estamos aplicando) y qué información no queremos (se quedará indicada, sin valor)
Ejemplo:
Obtener nombre de estudiante, curso y nombre del profesor del curso para todos los estudiantes que han obtenido nota ‘C’ en cursos de 5 créditos.
xxxxxxxxxx11MATCH (e:Estudiante)-[:EXAMINADO {nota:'C'}]-(c:Curso {creditos:5})-[:FUE_IMPARTIDA]-(p:Profesor) RETURN e.estudiante, c.titulo, p.profesorObtener nombre de todos los estudiantes que cursaron Griego Moderno o Español Moderno en 2019.
xxxxxxxxxx21MATCH (e:Estudiante)-[r1:EXAMINADO]-(c:Curso) WHERE r1.fecha IS NOT NULL and r1.fecha < date('2020-01-01') and r1.fecha >= date('2019-01-01') and c.titulo in ['Griego moderno','Español moderno']2RETURN e.estudianteObtener todos los datos de estudiantes, cursos y profesores para los estudiantes que cursaron Griego Moderno o Español Moderno en 2019.
xxxxxxxxxx21MATCH (e:Estudiante)-[r1:EXAMINADO]-(c:Curso)-[:FUE_IMPARTIDA]-(p:Profesor) WHERE r1.fecha IS NOT NULL and r1.fecha < date('2020-01-01') and r1.fecha >= date('2019-01-01') and c.titulo in ['Griego moderno','Español moderno']2RETURN e,c,p